
El principal resultado de este proyecto de investigación será, por tanto, un framework basado en un conjunto de organizaciones virtuales de agentes ligeros orientadas a la ingestión, securización, tratamiento y análisis de grandes volúmenes de datos que serán previamente caracterizados mediante ontologías y técnicas de anotación semántica de forma que se abstraiga el modelo de datos del modelo de negocio de las diferentes entidades usuarias en cada problemática que se aborde. Asimismo, el framework permitirá la transición entre datos masivos no estructurados en forma de data lakes semánticos hacia repositorios estructurados y se facilitará a la entidad usuaria diferentes servicios y recursos asociados a sus datos mediante algoritmos neuroevolutivos que optimicen la disponibilidad de los mismos. Mediante grafos de conocimiento, redes convolucionales, técnicas de agrupamiento basadas en clustering espectral y técnicas de inteligencia artificial explicable cada entidad podrá extraer las características más relevantes y obtener conocimiento sobre sus datos, así como generar explicaciones que permitan comprender los modelos y visualizaciones obtenidas utilizando un lenguaje natural.
Este nuevo framework resultante será validado en el proyecto LUCERNA mediante un demostrador en entorno de laboratorio, alcanzando, de este modo, un nivel de madurez TRL4.
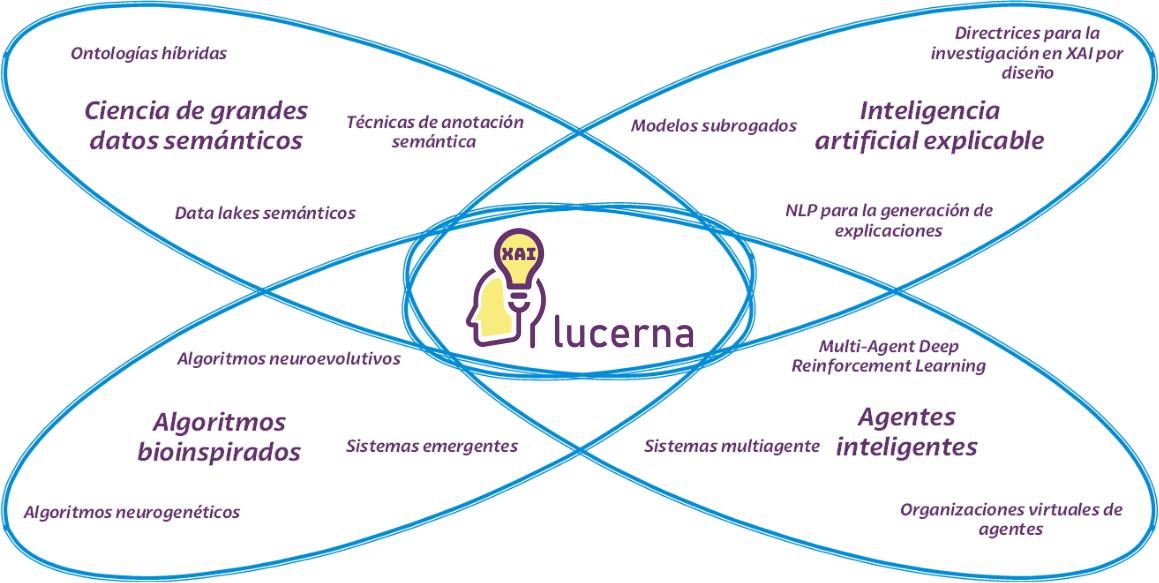
Áreas de investigación y pilares tecnológicos fundamentales del proyecto LUCERNA.